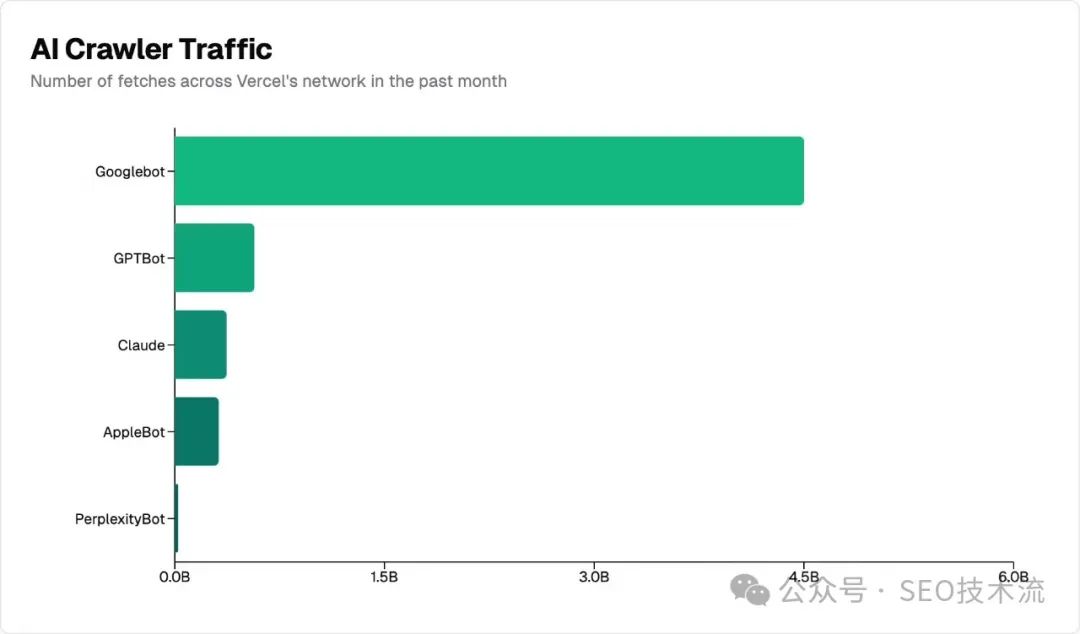
本文是 MERJ 和 Vercel 研究实际数据总结了目前主流 AI 爬虫的几个特征。 注:Vercel 是 Next.js 的前端云平台;MERJ 是数据驱动的营销公司;本文翻译自 Vercel 的 Blog 文章《The rise of the AI crawler》。 整体上,AI 爬虫已经成为网络上的重要存在。在过去一个月中,OpenAI 的 GPTBot 在 Vercel 网络上产生了 5.69 亿次抓取,而 Anthropic 的 Claude 紧随其后,达到了 3.7 亿次。 而这 2 个加起来的请求量只占同期 Googlebot 45 亿次抓取的 20%。 Vercel 网络上的 AI 爬虫流量非常大。在过去的一个月: GPTBot、Claude、AppleBot 和 PerplexityBot 合计抓取了近 13 亿次,约占 Googlebot 总抓取量的 28%+。 虽然AI 爬虫尚未达到 Googlebot 的规模,但他们已占据网络爬虫流量的很大部分。 这些 AI 爬虫都在美国数据中心: 相比之下,传统搜索引擎通常会将抓取分散到多个地区。例如,Googlebot 在美国七个不同的地区运营,包括达尔斯(俄勒冈州)、康瑟尔布拉夫斯(爱荷华州)和蒙克斯科纳(南卡罗来纳州)。 AI 爬虫在 JavaScript 渲染能力方面存在明显差异。为了验证我们的发现,我们分析了使用不同技术栈的 Next.js 应用程序和传统网页应用。 调查结果一致表明,目前主要的 AI 爬虫都不渲染 JavaScript。这包括: 研究结果还显示: 数据表明,虽然 ChatGPT 和 Claude 的爬虫确实会获取 JavaScript 文件(ChatGPT:11.50%,Claude:23.84% 的请求),但它们并不执行这些文件。它们无法读取客户端渲染的内容。 但请注意,包含在初始 HTML 响应中的内容(如 JSON 数据或延迟的 React Server Components)可能仍会被索引,因为 AI 模型可以解析非HTML内容。 相比之下,Gemini 使用 Google 的基础设施,使其具有与我们在 Googlebot 分析中记录的相同渲染能力,能够完整处理最新的网页应用。 AI 爬虫在抓取 nextjs.org 时表现出明显的内容类型偏好。最明显的特征有: 作为对比,Googlebot 的抓取量(包括 Gemini 和搜索)分布更加均匀: 这些模式表明AI 爬虫会收集多样化的内容类型——HTML、图片,甚至将 JavaScript 文件作为文本收集——这可能是为了训练他们的模型以适应各种形式的网页内容。 虽然像 Google 这样的传统搜索引擎已经针对搜索索引优化了他们的抓取模式,但较新的AI 公司可能仍在完善他们的内容优先级策略。 我们的数据显示AI 爬虫行为存在明显的低效现象: 对 404 错误的分析显示,除去 robots.txt 之外,这些爬虫经常尝试获取 /static/ 文件夹中的过期资源。这表明AI 爬虫需要改进 URL 选择和处理策略以避免不必要的抓取。 这些高比例的 404 错误和重定向与 Googlebot 形成鲜明对比 -Googlebot 仅有 8.22% 的请求遇到 404 错误,1.49% 的请求遇到重定向。这表明 Google 在优化其爬虫以抓取真实资源方面确实有更多经验。 我们对流量模式的分析揭示了爬虫行为和网站流量之间存在关联性。基于来自 虽然传统搜索引擎已经开发出复杂的优先级算法,但 AI 爬虫似乎仍在不断发展其网络内容发现方法。 优先对关键内容进行服务器端渲染。 ChatGPT 和 Claude 不执行 JavaScript,因此任何重要内容都应该在服务器端渲染。这包括主要内容(文章、产品信息、文档)、元信息(标题、描述、分类)和导航结构。SSR、ISR 和 SSG 能确保您的内容对所有爬虫都是可访问的。 客户端渲染仍适用于增强功能。 您可以放心地对非核心的动态元素使用客户端渲染,比如访问计数器、交互式UI增强功能、在线聊天小部件和社交媒体信息流。 高效的URL管理比以往任何时候都更重要。 AI 爬虫的高 404 错误率突显了维护适当重定向、保持站点地图更新以及在整个网站使用一致的 URL 模式的重要性。 使用 使用 Vercel 的 WAF 来阻止AI爬虫。 我们的"阻止AI机器人防火墙规则"让您只需一键就能阻止AI爬虫。这个规则会自动配置您的防火墙以拒绝它们的访问。 JavaScript 渲染的内容可能缺失。 由于 ChatGPT 和 Claude 不执行 JavaScript,它们对动态网络应用的响应可能不完整或过时。 注意信息来源。 较高的404错误率(>34%)意味着当 AI 工具引用特定网页时,这些 URL 很可能是错误的或无法访问的。对于重要信息,始终直接验证来源而不是依赖AI提供的链接。 预期更新的不一致性。 虽然 Gemini 利用 Google 的基础设施进行抓取,但其他 AI 助手显示出较不可预测的模式。有些可能引用较旧的缓存数据。 有趣的是,即使在向 Claude 或 ChatGPT 请求最新的Next.js文档数据时,我们通常在 我们的分析显示,AI 爬虫已经迅速成为网络上的重要存在,在 Vercel 的网络上每月有近 10 亿次请求。 然而,在渲染能力、内容优先级和效率方面,它们的行为与传统搜索引擎有明显不同。遵循已建立的网络开发最佳实践——特别是在内容可访问性方面——仍然至关重要。
规模和分布
爬虫位置分布
JavaScript 渲染能力
内容类型优先级
爬虫效率问题
流量相关性分析
nextjs.org 的数据:
建议
对于希望被抓取的网站站长
对于不希望被抓取的网站所有者
robots.txt 来控制爬虫访问。robots.txt 文件对所有爬虫都有效。通过指定AI爬虫的用户代理(user agent)或产品标识(product token)来设置具体规则,以限制对敏感或非必要内容的访问。要找到需要禁止的用户代理,您需要查看每个公司自己的文档(例如,Applebot和OpenAI的爬虫)。
对于 AI 用户
nextjs.org 的服务器日志中也看不到即时的获取请求。这表明AI模型可能依赖于缓存数据或训练数据,即使它们声称已获取最新信息。
总结
备注
文章为作者独立观点,不代表DLZ123立场。如有侵权,请联系我们。( 版权为作者所有,如需转载,请联系作者 )

网站运营至今,离不开小伙伴们的支持。 为了给小伙伴们提供一个互相交流的平台和资源的对接,特地开通了独立站交流群。
群里有不少运营大神,不时会分享一些运营技巧,更有一些资源收藏爱好者不时分享一些优质的学习资料。
现在可以扫码进群,备注【加群】。 ( 群完全免费,不广告不卖课!)







发表评论 取消回复