有人说搜索引擎技术似乎不需要本地化。这是完全不了解这个领域的人说的。当然,说实话,如果有人说谷歌在中文本地化方面做得非常好,我可以部分同意,同意的比例可能比谷歌工程师还少。但我相信谷歌的工程师也会告诉你,搜索引擎需要本地化。
今天写一篇关于搜索引擎的技术机制和市场竞争的一些特点的科普文章。当然,作为从事或者对流量运营感兴趣的朋友,你可以从另一个角度来理解这篇文章。
搜索引擎的核心技术架构包括以下三个部分:一是蜘蛛/爬虫技术;第二,指数技术;三是查询呈现技术;当然,我不是搜索引擎的架构师。我只能肤浅地做一个结构性的分割。
1.蜘蛛,又称爬虫,是一种从互联网上抓取和存储信息的技术。
很多不明所以的人对搜索引擎的信息收录有很多误解,以为是有偿收录,或者有什么其他特殊的投稿技巧。事实上,他们不是。搜索引擎通过互联网上一些知名网站抓取内容并分析链接,然后有选择地抓取链接中的内容,再对链接进行分析。以此类推,通过有限的入口,他们基于彼此的链接,形成了强大的信息抓取能力。
有些搜索引擎本身也有链接提交入口,但基本上,并不是主要的入口。不过作为创业者,建议了解一下相关信息。百度和google都有站长平台和管理背景,这里的很多内容需要非常非常认真的对待。
反过来,在这个原则下,一个网站只有被其他网站链接,才能被搜索引擎抓取。如果这个网站没有外部链接,或者外部链接在搜索引擎中被认为是垃圾或者无效链接,那么搜索引擎可能不会抓取他的页面。
而分析判断搜索引擎是否或何时抓取了你的页面,只能通过服务器上的访问日志来查询。如果是cdn的话,会比较麻烦。但是无论如何在网站中嵌入代码,比如cnzz、百度统计或者google analytics,都无法获取蜘蛛抓取的信息,因为这些信息不会触发这些代码的执行。
推荐的日志分析软件是awstats。
十几年前,分析百度蜘蛛的抓取轨迹和更新策略是很多草根站长的日常功课。比如某知名80后上市公司董事长,现在身价几十亿,当年在一个站长论坛上就用这个精准的分析判断封神了。很小的时候就已经是站长圈的偶像了。但是蜘蛛的话题不仅仅是基于链接抓取,还有扩展。
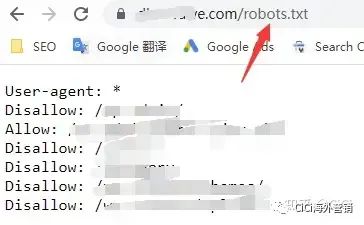
首先,网站所有者可以选择是否允许蜘蛛抓取。有一个robots.txt文件来控制这一点。
一个典型的例子是https://www.taobao.com/robots.txt.
如你所见,淘宝仍有关键目录不对百度蜘蛛开放,而是对google开放。
另一个经典案例是http://www.baidu.com/robots.txt.
你看到了什么?也许你什么都没看见。我提醒你一下,百度实际上是完全禁止360蜘蛛抓取的。
但是这个协议只是一个约定,实际上并没有约束力。所以,你猜,360遵守百度的蜘蛛抓取禁令了吗?
其次,最早的抓取是基于网站之间的链接,但实际上并不能肯定的说可能还有其他的抓取入口,比如,
插件或浏览器,免费网站统计系统的内嵌代码。
会不会成为蜘蛛抢夺的入口?我只能说有可能。
所以我跟很多创业者说,如果中国做网站,发布百度统计,海外网站,发布google analytics,会增加你的网站被搜索引擎收录吗?我只能说猜测,有可能。
第三,无法捕捉的信息。
有些网站是用javascript特效链接的,比如浮动菜单等。这种连接可能不会被搜索引擎的蜘蛛程序识别。当然,我只是说有可能。现在搜索引擎比以前更智能了。十几年前很多特效环节别的都不知道,现在会更好。
需要登录注册的页面,蜘蛛是无法访问的,也就是无法收录。
有些网站会给出专门的页面进行搜索,也就是蜘蛛来了就能看到内容(蜘蛛访问会有专门的客户端标记,服务器识别和处理也不复杂)。人来了要登录才能看到,但这其实是违反收录协议的(需要人和蜘蛛看到相同的内容,这是大部分搜索引擎的收录协议),可能会受到搜索引擎的惩罚。
所以一个社区要想通过搜索引擎带来免费用户,就必须让访客看到内容,哪怕是一部分。
带有许多复杂参数的内容链接URL可能会被蜘蛛作为重复页面拒绝。
很多动态页面都是由一个带参数的脚本程序来体现的,但是蜘蛛发现同一个脚本有大量的参数,有时候会给这个页面的价值评估带来麻烦。蜘蛛可能会认为这个页面是一个重复的页面,并拒绝包括它。还是那句话,随着技术的发展,蜘蛛在识别动态脚本的参数方面已经有了很大的进步,现在已经基本不需要考虑这个问题了。但这就诞生了一种技术,叫做伪静态。通过配置web服务器,用户访问的页面的url格式看起来是静态页面,但实际上后面是常规匹配,实际执行的是动态脚本。
为了追求免费搜索,许多社区论坛已经伪静态化。十几年前,几乎是草根站长的必备技能之一。
爬虫技术暂时放在这里,重点在这里。有外链不代表搜索蜘蛛会爬。如果搜索蜘蛛抓取,不代表搜索引擎会收录。搜索引擎收录,不代表用户可以搜索;
站点语法是检查一个网站条目数量的最基本的搜索语法。我开始以为是个常识,后来在新加坡做了一些创业培训才发现。大部分刚进入这个行业的人,或者有意进入这个行业的人,对这个行业一无所知。
举个例子,百度搜索site:4399.com。
2.指标系统
蜘蛛抓取的是网页的内容,所以如果想让用户通过关键词快速搜索到这个网页,就必须用关键词索引网页,这样才能提高查询效率。简单来说,就是从网页中提取出每个关键词,针对这些关键词的出现频率、位置、特殊标记等诸多因素赋予不同的权重,然后存储在索引数据库中。
那么问题来了,关键词是什么。
在英语中,如这是一本书,在汉语中,这是一本书。
英语自然是四个字,空格是自然参与者。语文呢?不能把一个句子作为关键词(如果你把一个句子作为关键词,那么当你搜索一些信息的时候,你就无法获得索引命中。比如你搜索一本书,却找不到,这显然不符合搜索引擎的诉求)。所以分词。
刚开始,最简单的想法就是每一个字都剪。这曾被称为词索引。每个单词都有索引,并标出其位置。如果一个用户搜索一个关键词,它也会把这个关键词拆分成单词来搜索并组合结果,但这时问题就出现了。
比如搜索关键词“海鲜”,会出现一个结果,上海鲜花,显然不是正确的搜索结果。
比如搜索关键词“和服”,就会出现结果、交换机、服务器。
这些都是谷歌在野时期无法幸免的问题。
后来有了梗。不要笑。这些都是血泪梗。他们半夜给我打电话,说网监通过搜索发现你们小区有淫秽内容,要求删除。否则,他会关闭你的网站。他半夜醒来,仔细调查了一番。他百思不得其解,求信息线索。最后他发现有人发了个小广告,“买二十四个开关”。还有就是涉嫌政治敏感。最终找到了“提供三台独立服务器”。你看到敏感词了吗?你不应该受委屈。这两个故事不一定是真的,因为都是在网上看到的,但是我想说,这样的事情确实存在,也不全是空穴来风。所以分词是很多亚洲语言需要额外处理的问题,而西方语言不存在。
但是分词并不是说说那么简单,比如以下几点:1。如何识别人的名字?2.如何识别网络新词?比如“不知情”。3.中英文混合的坑,比如QQ表情。
做一个分词系统说到底并不难,但要做一个能自动学习、与时俱进、高效灵活的分词引擎,技术上还是很难的。当然,我不是这方面的专家,所以不敢妄言。
现在机器学习技术发达,特别是谷歌在深度学习领域有领先优势。在过去,许多人工校准和分类工作可以通过算法来完成。某种意义上,本地化工作可以通过机器学习来完成;在未来,也许深度学习技术可以自己学习和掌握本地化技能。但我想提出两点。第一,从搜索引擎发展的历史来看,在深度学习技术尚未成熟的情况下,本地化非常重要,也是决定竞争成败的重要因素。第二,即使深度学习现在已经非常强大了,但是在人工参与、标定、测试、反馈当地语言的基础上,一些本地化工作仍然对深度学习的效率和效果起到了不可替代的作用。
除了分词,还有一些索引系统的关键点,比如实时索引,因为索引数据库的更新是一个大动作。一般网站运营者都知道,自己的网站内容更新后,需要等待索引数据库的下一次更新才能看到效果。而且,对于不同权重的网站内容,索引数据库的更新频率是不同的。但比如一些高优先级的资讯网站和新闻搜索,索引数据库几乎可以实时索引,所以我们在新闻搜索中已经可以搜索到几分钟前的信息了。
我曾经抱怨过一件事。每次我在百度空间发表文章,google都率先索引。当时他们的解释是,猜测是很多人通过google Reader订阅了我的博客,大概是google快速索引的入口。(不过,百度空间没了,谷歌阅读器也没了。)
指标体系的权重体系是所有SEOER最关心的问题。他们往往以不同的方式组合策略,观察搜索引擎的收录、排名、路线,然后通过对比分析整理出相关策略。这个东西可以写很久,今天就不提了。
但是让我告诉你一个事实。很多外面的公司,做SEO的,误以为百度内部的人熟悉这里的门道和规则。很多人花高价挖百度的搜索产品经理和技术工程师做SEO。结果,呵呵呵呵。而外面那些草根创业者,有一些是擅长这个的,真的比百度的更懂,搜索权重的影响力,更新的频率等等。比如前面提到的那个身价几十亿的80后创业者。基于结果反推策略,比身处其中但不了解全局的参与者更能发现系统的关键点。是不是很有意思?
3.查询和显示
在用户的浏览器或者手机客户端输入一个关键词,或者几个关键词,甚至一个词。这是在服务器端,响应程序的后处理步骤如下
第一步,检查最近是否有人搜索过同一个关键词。如果有这样的缓存,最快的处理方式就是提供给你,这样查询效率最高,后端负载压力最低。
第二步:如果发现这个输入的查询最近没有被搜索过,或者由于其他条件必须更新结果,那么这个用户输入的单词就会被切分。没错,如果不止一个关键词或者一句话,答题程序会再次对搜索到的查询进行分段,拆分成几个不同的关键词。
第三步:将切分后的关键词分发给查询系统,查询系统会查询索引数据库,这是一个庞大的分布式系统。首先分析这个关键字属于哪个块和服务器,索引是有序的数据组合。我们可以用近似二分法来思考。不管数据有多大,都可以用二分法查找一个结果,查询频率为log2(N),保证了在海量数据下,查询一个关键词当然实际情况会比二分法复杂很多,更容易理解。不是不告诉你,是我自己不知道。
第四步:将不同关键词的查询结果(只是部分按权重排序的前几名结果,肯定不是全部结果)根据权重逆序再次汇总在一起,然后反馈共同命中的部分,做出最终的权重排序。
记住,搜索引擎永远不会返回所有结果。这个费用谁也承担不起,百度不行,谷歌也不行,而且翻页也有限制。
请记住,如果在您的多个关键字中有许多不同类别的冷门词,搜索引擎可能会丢弃其中的一个,因为摘要数据很可能不包含常见的结果。搜索技术不应该被神话,这样的例子偶尔会出现。
这是三个主要部分。更确切的说,其实还有第四部。
单击用户行为收集和反馈部分。
基于用户的翻页和点击分布,可以判断搜索结果的好坏,调整权重。不过这个早期的搜索引擎是没有的,只是后来才有,所以暂时不列为必备的三块。
此外还有一些搜索优化的机器学习策略,易混淆词和同音词的识别等。也都是基于用户行为反馈,这是另一个故事,这里不展开。
关于第四部,我以前说过一句话,点击求权。我说这个词值一千块,估计很多人没看懂。只要我不懂,不然会被一些同行骂死的。以上只是指搜索引擎的工作原理,以及一些技术逻辑。当然只是入门级的解读。毕竟我也没法再解释了。
但是搜索引擎的本地化并不局限于搜索技术的本地化。
百度是强大的,不仅仅是在搜索技术上。当然,有人会说百度没有搜索技术,这个说法我就不争论了。我不是想改变谁的观点,我只是列举一些事实。
百度的实力也来源于两大块,第一块是内容护城河,第二块是入口控制。
前者是百度贴吧、百度mp3、百度知道、百度百科、百度文库。
后者是hao123和百度联盟。
两者都是本地化的。谷歌进入中国,两者都有动作。
投资天涯,收购265,大力发展谷歌联盟,都是本地化。
另外重申一下,百度家族桶的出现以及百度家族桶与hao123的绑定是在360崛起之后。在百度收购和360崛起之前,hao123已经悄然推广和捆绑。从历史事实出发,请不要把本土化等同于流氓行为。
文章为作者独立观点,不代表DLZ123立场。如有侵权,请联系我们。( 版权为作者所有,如需转载,请联系作者 )

网站运营至今,离不开小伙伴们的支持。 为了给小伙伴们提供一个互相交流的平台和资源的对接,特地开通了独立站交流群。
群里有不少运营大神,不时会分享一些运营技巧,更有一些资源收藏爱好者不时分享一些优质的学习资料。
现在可以扫码进群,备注【加群】。 ( 群完全免费,不广告不卖课!)





发表评论 取消回复