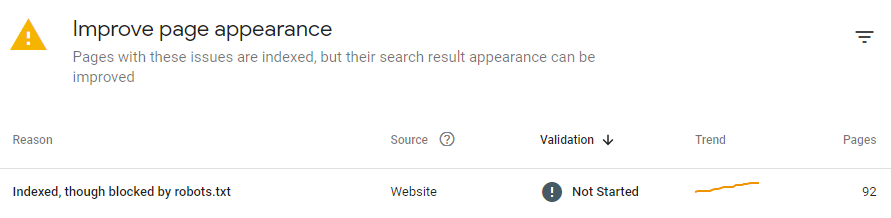
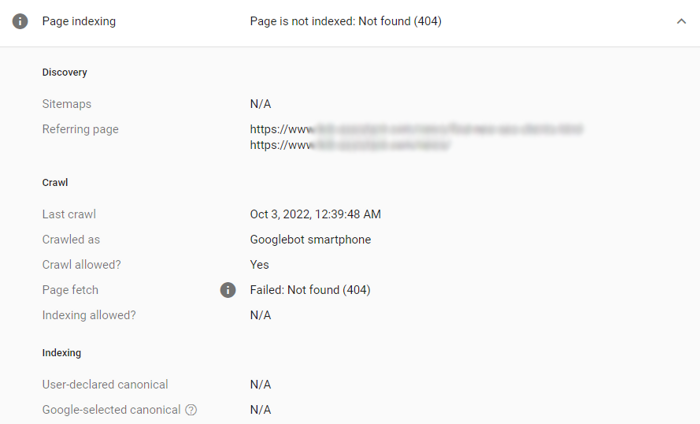
收录对于GoogleSEO至关重要。 如果谷歌没有收录你的网页,你所做的一切SEO工作都会变得毫无价值,哪怕你已经针对一个页面进行了臻于完美的优化,并能确保它将带来绝佳的用户体验。残酷的现实是:未被收录的页面不会进入搜索结果页(SERP),也不会带来任何流量和转化。 同样,如果谷歌偶然收录了一个本不应该被收录的页面,那么你就有可能面临私人信息泄露、收到谷歌对低质量内容的惩罚等其他严重的后果。 ▊ 在本指南中,我们将探索Google收录的常见问题,以及如何解决它们。但首先,让我们来看看如何检查你的网站是否存在收录问题。 01 如何发现收录问题? Google SearchConsole可以帮助你发现你的网站存在哪些收录问题,请点击收“收录”(Index)>“页面”(Page)以查看,如下图所示。 只要是未被Google收录的页面,不管是因为什么原因,都会统一显示在“未收录”(NotIndexed)部分。被Google收录,但是存在其他问题等待你解决的页面将会显示在底部的“改善页面外观”(Improvepage appearance)部分。 Google SearchConsole将提供更多细节,帮助你确定页面的问题所在,如下图: 在了解如何发现网站存在的收录问题后,我们可以探讨解决方案啦。当然,本文探讨的所有解决方案,都是针对需要收录的网页。如果你的页面不需要被Google收录,你可以采用noindex标签,或者通过robots.txt指令的限制Google访问相关页面。此外,确保将这些网页从你的网站地图(sitemap)中删除。当然,如果这些页面本就未被收录,那么你无需采取任何行动。 02 如何解决Google收录问题? 1️⃣404错误:网页未找到(Not found 404) 404网页未找到(Notfound404),或者失效URL,应该是最常见的收录问题之一。很多原因都可能导致HTTP状态码出现404,比如,你已经删除了URL,但没有从网站地图(sitemap)中或站内其它页面中删除该失效URL,URL有误,等等。 Google曾提示404本身并不损害网站性能,除非这些URL是主动提交给Google收录的URL。那么,如果你在收录报告中看到404网址,应该如何修复呢?我们提供以下解决方案: ● 更新你的网站地图(sitemap),检查受影响的URL是否有误。 ● 如果该页面已经迁移到一个新的地址,设置一个301重定向。 ● 如果该页面已经被删除,也没有任何替换网页,那么将其保留为404,但从网站地图(sitemap)中删除,假如站内其它页面有链接到该页面,该内链也需要同步删除或更新。这样,Google就不会再试图找到并抓取这个页面了。 ● 如果你需要保留404,那就创建一个用户友好型404页面--你可以在那里添加一些有用的链接,使用户继续停留在你的网站上,而不是直接关闭页面。但有一点需要记住,404页面的性质并不会因此改变,你依旧应该禁止Google收录它。 ● 请注意,Google Search Console现在并不区分404(Not found,未找到)和410(gone,已消失),而是将它们都分类进404报告中。这两个代码曾经是不同类型的响应代码。404意味着 "没有找到,但以后也许可以找到",而410代表 "现在没有找到,未来也不会找到,因为它已经永远消失了"。现在,Google对404和410页面采取的措施是一样的。 所以,如果你在404报告中发现一个410的页面,不要感到奇怪。我们建议你不要保留空的410页面,而是设置一个自定义的404页面,降低用户跳出率。许多SEO从业者和站长有一个习惯,就是把404重定向到网站主页,但事实上,这并不是最好的做法。它会让Google觉得混乱,并导致“软404”(Soft 404)。 2️⃣软404错误(Soft 404) 当一个网页,HTTP状态码出现200(服务器成功返回网页),但Google无法找到它的内容并认为它是一个404错误的时候,就会出现软404(Soft404)问题。软404的出现通常是由以下原因造成的: ① 服务器端文件丢失 ② 与数据库的连接中断 ③ 网站的内部搜索页结果为空 ④ 未加载或丢失JavaScript文件 ⑤ 页面内容太少 ⑥ 页面隐蔽 这些问题实际上并不难解决,下面是一些常见的解决方案: ● 如果网页内容已经迁移,该页面内容为空,且HTTP状态码显示200 OK,那么设置一个301重定向到新的地址。 ● 如果被删除的内容页没有替代页,请将其标记为404并从网站地图(sitemap)中删除。 ● 如果该页面应该存在,请丰富该页面内容,并检查该页面上的所有脚本是否被正确渲染和显示(例如被robots.txt禁止,浏览器不支持,等等)。 ● 如果错误发生的原因是Google bot试图获取该页面时,服务器出现故障,请检查服务器是否正常工作,然后要求Google重新收录该网页。 3️⃣401错误:网页未授权 HTTP401错误代表Googlebot没有网页访问权限,需要进行身份认证。如果你希望该页面被收录,请授予Googlebot相关的权限,或者删除网页的授权要求。 4️⃣403错误:访问被禁止 这种类型的错误发生在用户代理提供了进入该页面的凭证(登录、密码),但“执行”访问被禁止。所以服务器返回403,而不是预期的页面。 如果一个页面被错误地禁止访问了,而你又确实需要Google收录它,那么你应该允许未登录的用户访问该页面,或者允许Googlebot进入该页面,以阅读和收录它。 5️⃣网址已提交,但带有“noindex”标记 当你明确要求谷歌收录一个页面(即把它添加到网站地图或手动请求Google收录),但该页面有一个noindex标签时,这个错误就会发生。解决方案很简单--删除noindex标签,谷歌就可以访问并收录该页面。 6️⃣robots.txt设置了不可被抓取 如果你通过robots.txt屏蔽了某个页面,那么谷歌将不会抓取收录它。只要移除这些限制,Google就会收录这个页面。 ⚠注意:Robots.txt并不能确保一个网页不被收录。有时,GoogleSearch Console可能会显示:“已收录,尽管遭遇robots.txt阻止(Indexed,though blockedby robots.txt)” 这种情况比未被Google收录要麻烦得多。因为Google可能会访问一些私密信息(比如购物车、私人数据等),并将其展示在搜索结果页。 如果遇见这种情况,请先确认是否需要Google收录该页面。如果是,从robots.txt文件中删除该网页URL。如果不是,也需要把这个URL从robots.txt中删除,但同时应用noindex标签,或限制非授权用户的访问。在采取限制措施后,你也可以通过GoogleSearch Console选择“收录(index)”>“移除(Removals)”>“新请求(Newrequest)”要求谷歌从收录中移除该网页。 以上六个常见问题的解决方案学会了吗?在下一篇文章中,我们将继续聚焦Google收录的疑难杂症!快点关注和收藏,才不会错过《Google收录的常见问题及解决方案指南(下)》更新!






文章为作者独立观点,不代表DLZ123立场。如有侵权,请联系我们。( 版权为作者所有,如需转载,请联系作者 )

网站运营至今,离不开小伙伴们的支持。 为了给小伙伴们提供一个互相交流的平台和资源的对接,特地开通了独立站交流群。
群里有不少运营大神,不时会分享一些运营技巧,更有一些资源收藏爱好者不时分享一些优质的学习资料。
现在可以扫码进群,备注【加群】。 ( 群完全免费,不广告不卖课!)





发表评论 取消回复