今天带大家了解url参数,也就是url parameters。
1 什么是url参数?
查询参数主要用于指定和排序网页上的内容,但它们也经常用于流量跟踪。
这是带有 URL 参数的 URL 的示例:

URL 参数(也称为查询字符串或 URL 查询参数)是插入到 URL 中的元素,可帮助您过滤和组织内容。或者在您的网站上实施跟踪。
要识别 URL 参数,请查看 URL 中问号 (?) 后面的部分。
URL 参数包括由等号 (=) 分隔的键和值。然后,多个参数用与号 (&) 分隔。
带有参数的完整 URL 字符串如下所示:
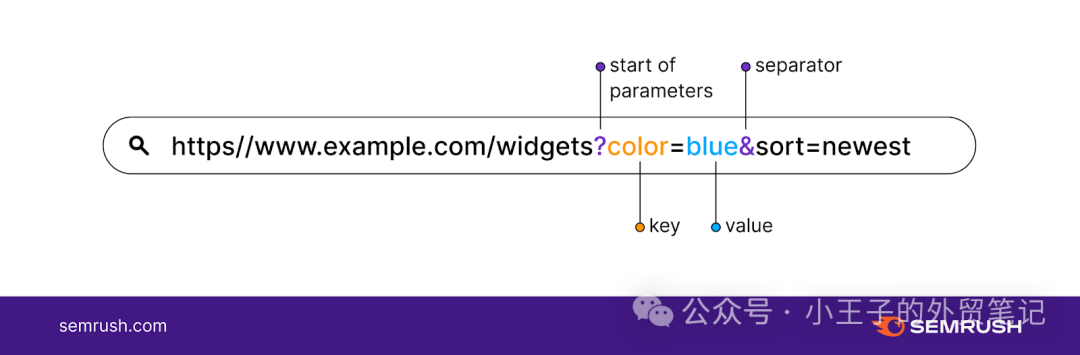
在上面的例子中,有两个参数:
值为“蓝色”的“颜色”
“排序”,值为“最新”
这会过滤网页以显示蓝色产品,并从最新的产品开始排列它们。
URL 参数将根据具体的键和值而变化。并且可以包括许多不同的组合。
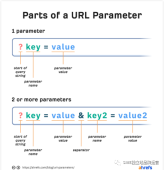
但基本结构(如下所示)始终类似于“https://www.domain.com/page?key1=value1&key2=value2”。

以下是每个部分的含义:
Key1:第一个变量名称
Key2:第二个变量名称
Value1:第一个属性值
Value2:第二个属性值
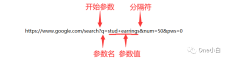
? : 查询字符串开始
= : 值分隔符
&:参数分隔符
还可以有其他键和值来形成更复杂的 URL 参数。
2 URL 参数有什么用?
使用 URL 参数的原因有很多。最常见的是:
排序和过滤:参数通常用于大型电子商务网站(或类似网站),以允许用户动态生成应用了所需排序或过滤的页面
例如 /dresses?sort=az、/womens-shoes?color=red 或 /hotels/seattle-wa? rating=5-star
分页:参数可用于识别存档或搜索结果的多个页面
例如/blog/all-articles?page=3
站点搜索:参数可用于传递某人在站点搜索中使用的搜索查询
/搜索?q=圣诞节
Translation:参数可用于语言选项
/home?lang=fr
描述:参数可用于传递产品的详细信息
/产品?sku=12345
跟踪:参数可用于特定的广告活动或按钮点击,以便能够跟踪通过该活动或按钮产生的流量
例如 /landingpage?utm_campaign=fbid_holidaypromo
3 为什么URL 参数对SEO很重要?
尽管 URL 参数对于经验丰富的 SEO 专业人士来说非常宝贵,但它们通常会给您网站的排名带来严峻的挑战。
当涉及到 URL 参数时,有一些 SEO 考虑因素,主要是因为参数的使用可能会导致大量内容非常相似的页面。当用户完成操作而没有实际更改页面上的内容时,有时会动态生成参数。这可能会导致一些常见的 SEO 问题:
重复内容:如果我们有很多不同的 URL,它们都是同一页面的参数化版本,我们不希望搜索引擎爬虫将这些视为重复内容,这是一个问题,因为像 Google 这样的搜索引擎将其视为低优质内容。
浪费抓取预算:从抓取预算的角度来看,重复内容也是一个问题。如果搜索引擎爬网程序正在爬网许多属于同一页面的所有版本的 URL,则它们可能不会预算足够的资源来爬网独特且有价值的页面。
页面排名信号的稀释:如果其他网站由于参数使用而链接到您的 URL 的不同版本,则这些反向链接的价值将分散在同一页面的多个版本中。这些页面最终可能会蚕食您主页的排名。
跟踪问题:如果您使用 Google Analytics 等跟踪工具,许多报告都是基于确切的 URL。如果同一页面有许多使用参数的不同版本,则每个版本都会单独显示在您的报告中(除非您设置特殊配置来解决此问题)。
URL 参数是一个有用的工具,特别是在管理具有大量页面、产品的网站或依赖于对各种活动的可靠跟踪的营销策略时。那么我们如何确保可以有效地使用 URL 参数而不损害 SEO 性能呢?
4 如何使用 URL 参数(附示例)
URL 参数通常用于对页面上的内容进行排序,使用户更轻松地导航产品。就像在网上商店一样。
这些查询字符串允许用户根据自己的特定需求订购页面。
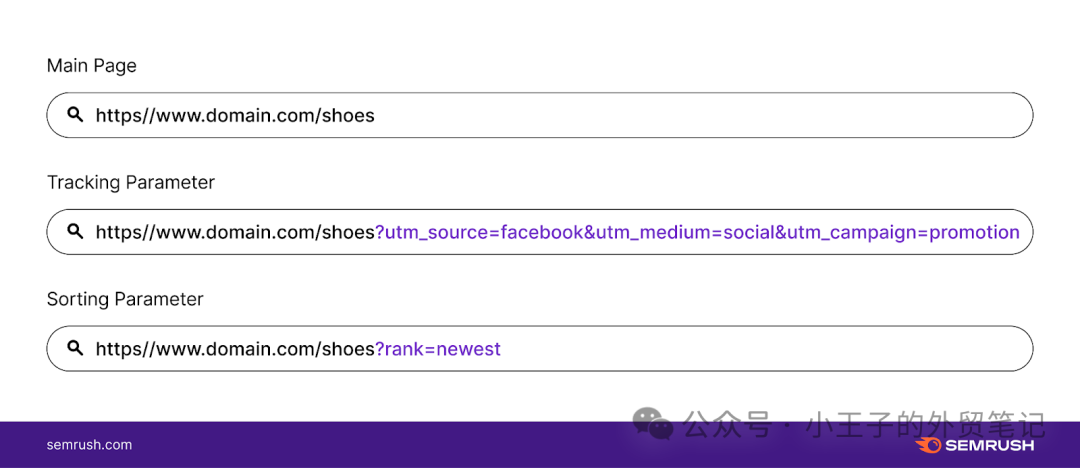
跟踪参数的查询字符串也同样常见。
数字营销人员经常使用它们来监控流量的来源。因此,他们可以跟踪他们的社交媒体帖子、广告活动和/或电子邮件通讯如何促进网站访问。
下面是跟踪和排序参数的样子:
5 URL 参数如何工作?
根据 Google 的说法,URL 参数主要有两种类型。它们的工作方式取决于类型:
内容修改参数(活动):将修改页面上显示的内容的参数。例如,“https://domain.com/t-shirts?color=black”将更新页面以显示黑色 T 恤。
跟踪参数(被动):将记录信息的参数,例如用户来自哪个网络、用户点击了哪个广告系列或广告组等,但不会更改页面上的内容。自定义 URL 可用于高级跟踪。
例如:
“https://www.domain.com/?utm_source=newsletter&utm_medium=email”将跟踪电子邮件通讯的流量。
“https://www.domain.com/?utm_source=twitter&utm_medium=tweet&utm_campaign=summer-sale”将跟踪 Twitter 活动的流量。
6 URL 查询字符串示例
我们已经介绍了查询字符串的几种不同的有益方式。
但 URL 参数有许多常见用途:

URL 参数何时成为 SEO 问题?
大多数人建议尽可能远离 URL 参数。
这是因为无论 URL 参数多么有用,它们都会产生可爬行性和可索引性问题。
结构不良、不更改页面内容的被动 URL 参数可能会创建无数具有相同内容的 URL。
7 URL参数导致的SEO问题
由 URL 参数引起的最常见 SEO 问题是:
重复内容:由于搜索引擎将每个URL视为单独的页面,因此由 URL 参数创建的同一页面的多个版本可能会被视为 重复内容。因为根据 URL 参数重新排序的页面通常与原始页面非常相似。并且某些参数可能会返回与原始页面完全相同的内容。
抓取预算浪费:具有多个参数的复杂 URL 会创建许多指向相同(或相似)内容的不同 URL。 据谷歌称,爬虫最终可能会浪费带宽或无法为网站上的所有内容建立索引。
关键字蚕食:原始 URL 的过滤版本针对相同的关键字组。这会导致多个页面竞争相同的关键字。这可能会让搜索引擎感到困惑,不知道哪些竞争页面应该针对该关键字进行排名。
稀释的排名信号:当您有多个具有相同内容的 URL 时,人们可能会链接到该页面的任何参数化版本。这可能会导致您的主页整体排名不佳。
URL 可读性差:参数化的 URL 对于用户来说实际上是不可读的。当显示在 SERP 中时,参数化 URL 看起来不可信,从而降低用户点击该页面的可能性。
如何管理 URL 参数以实现良好的 SEO
上面提到的大多数 SEO 问题都指向同一件事:对所有参数化 URL 进行爬行和索引。
但值得庆幸的是,SEO 对于通过参数无休止地创建新 URL 并非无能为力。
以下是你可以实施的一些解决方案。
使用一致的内部链接
如果您的网站有许多参数化 URL,则务必通过一致链接到静态非参数化页面来向爬虫发出信号,告知哪些页面不应编制索引。
例如,以下是来自在线鞋店的一些参数化 URL:
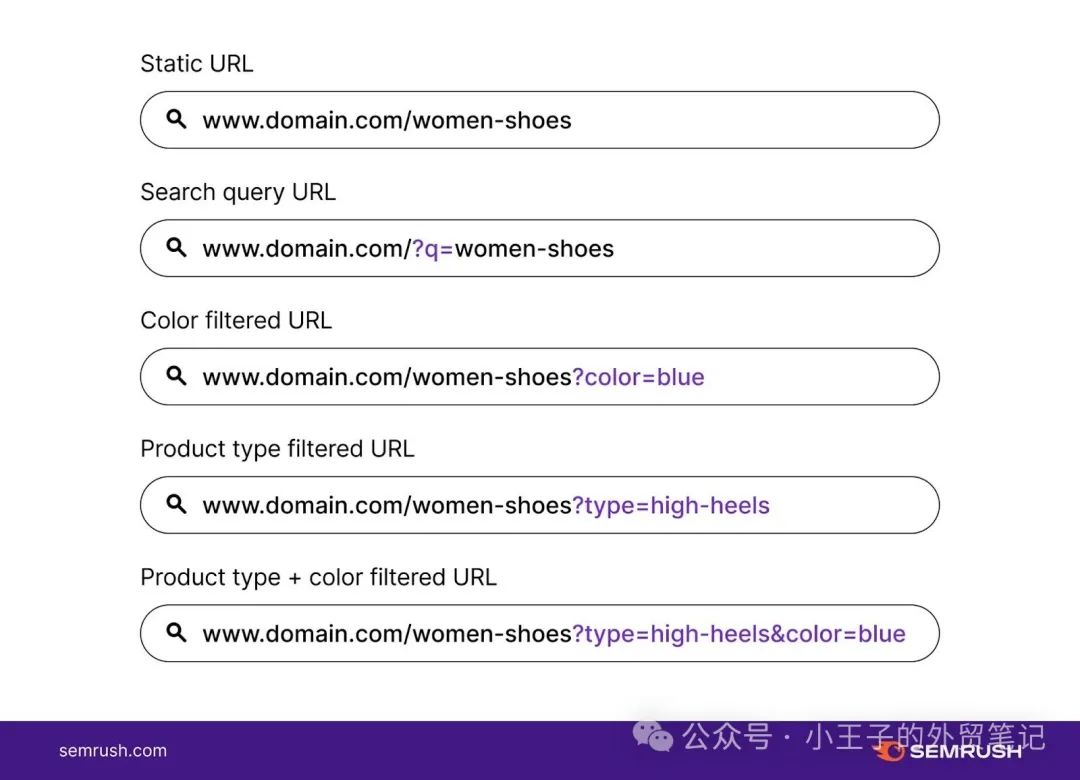
在此类情况下,务必小心并始终仅将内部链接添加到静态页面,而不要添加到带有参数的版本。
这样,您就可以向搜索引擎发送一致的信号,了解哪个版本的页面很重要并且应该建立索引。
规范化 URL
在参数化 URL 上设置 规范标签,引用您首选的 URL 进行索引。
如果您已创建参数来帮助用户浏览您的在线鞋店,则所有 URL 变体都应包含将主页标识为规范页面的规范标签。
这意味着在下图中,“https://www.domain.com/shoes/women-shoes?color=blue”和“https://www.domain.com/shoes/women-shoes?type=high” -heels”应该引用“https://www.domain.com/shoes/women-shoes”的规范链接。
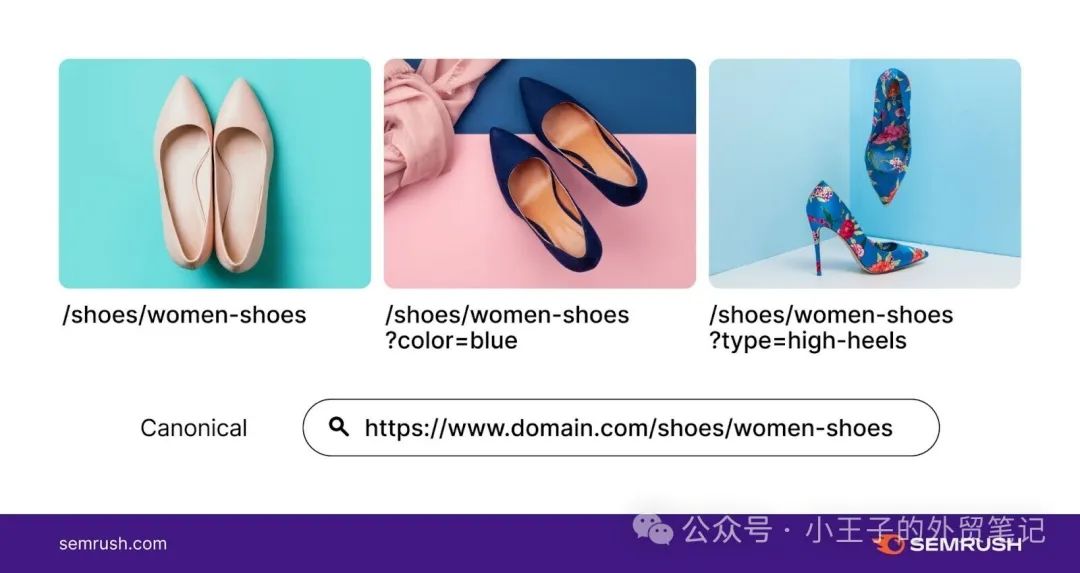
这将向爬虫发送一个信号,表明只有规范的主页才会被索引。而不是参数化的 URL。
通过 Disallow 阻止爬虫
如果您遇到抓取预算问题,您可以选择使用robots.txt 文件阻止抓取工具访问您的参数化网址。
机器人在抓取网站之前会检查 robots.txt 文件。他们将按照有关避免抓取哪些页面的说明进行操作。
以下 robots.txt 规则将禁止任何带有问号的 URL,即您的参数化 URL:
User-agent: *
Disallow: /*?*
使用 Semrush 的站点审核工具
当您想要了解网站 SEO 运行状况的概览时,避免抓取参数化 URL 非常重要。因此,您可以确保只审核重要的 URL。
设置 Semrush Site Audit时,您可以配置该工具,使其从爬网中排除参数化 URL。设置过程如下所示。
首先,打开该工具。输入您的域名并单击“开始 审核”。
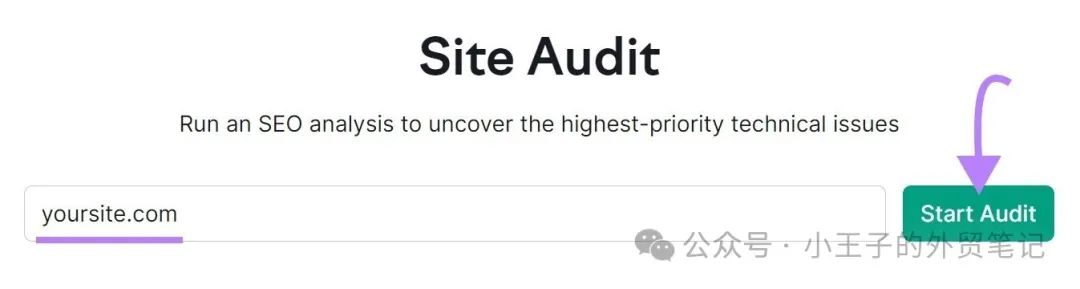
将弹出“站点审核设置”窗口。
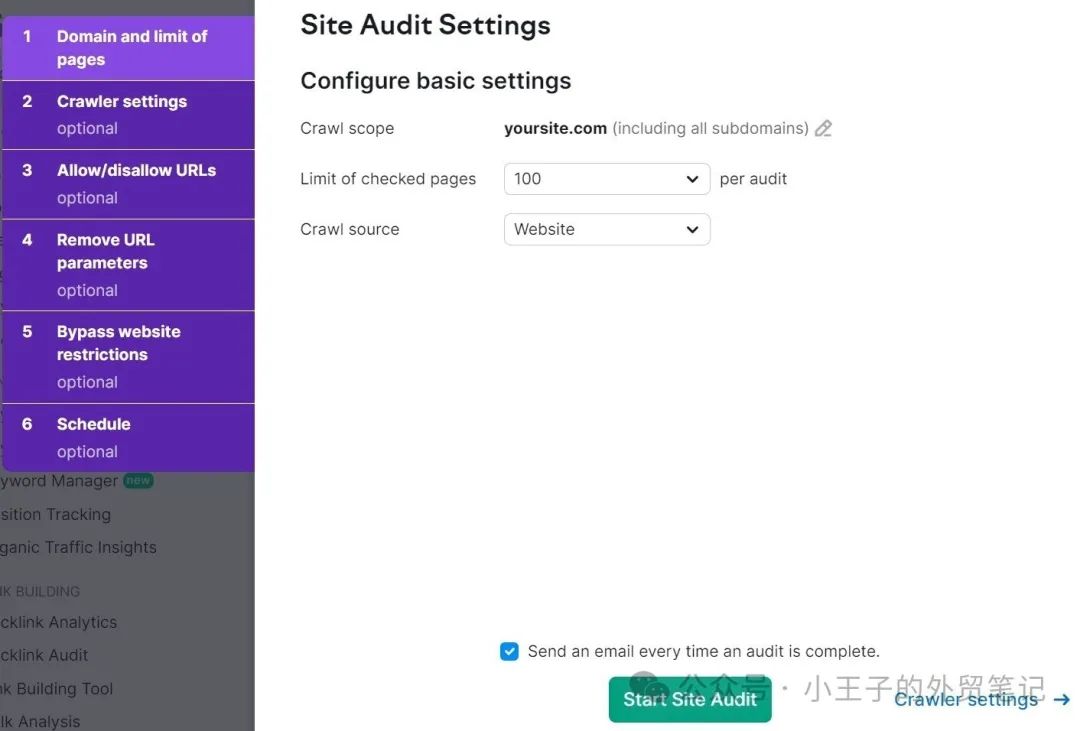
单击“删除 URL 参数”并列出您想要避免抓取的参数。
例如,如果您想排除分页参数(“?page=1”、“?page=2”、“?page=3”等),请在选项卡右侧的框中提及“page”。
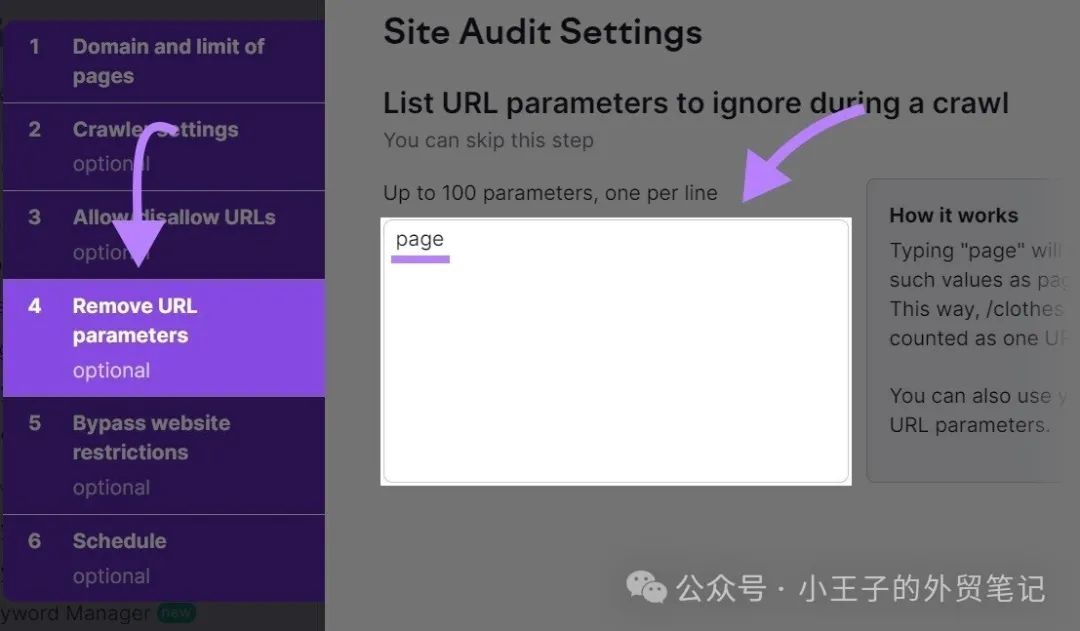
这将确保该工具避免抓取在其 URL 参数中包含关键“页面”的 URL。
列出要忽略的所有参数后,单击“开始站点审核”。
该工具将生成一份报告,为您提供站点技术运行状况的概述。
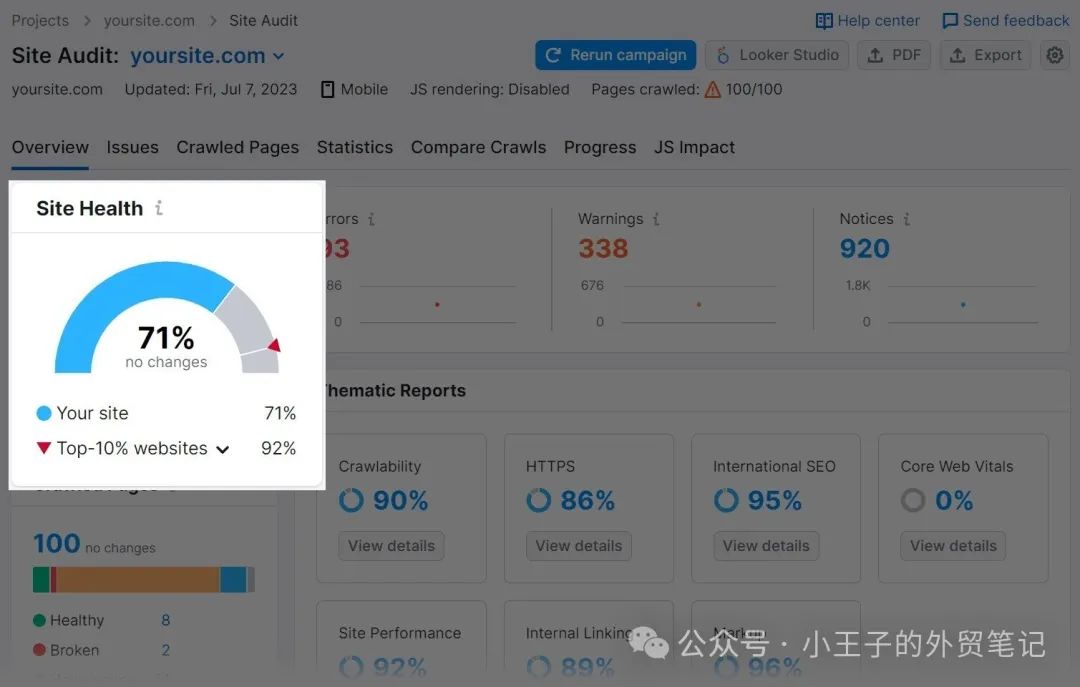
以及它在您网站上发现的一些主要问题。
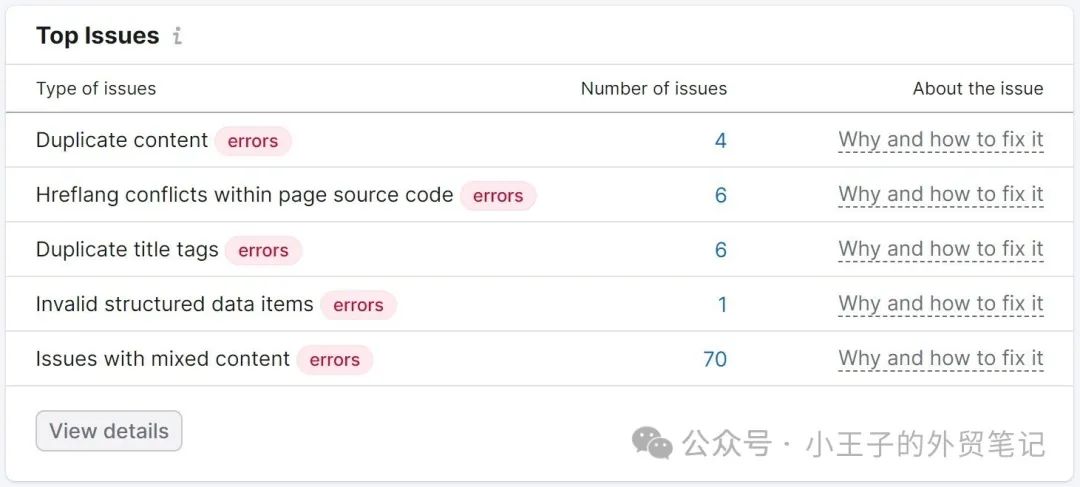
然后,您可以查看每个问题。并采取措施修复它们。
处理 SEO 的 URL 参数
参数化 URL 使修改内容或在网站上实施跟踪变得更加容易,因此值得在需要时使用它们。
您需要让网络爬虫知道是否使用参数来爬网 URL。并突出显示最有价值的页面版本。
花点时间决定哪些网址不应被编入索引。随着时间的推移,网络爬虫将更好地了解如何导航和处理网站的页面。
文章为作者独立观点,不代表DLZ123立场。如有侵权,请联系我们。( 版权为作者所有,如需转载,请联系作者 )

网站运营至今,离不开小伙伴们的支持。 为了给小伙伴们提供一个互相交流的平台和资源的对接,特地开通了独立站交流群。
群里有不少运营大神,不时会分享一些运营技巧,更有一些资源收藏爱好者不时分享一些优质的学习资料。
现在可以扫码进群,备注【加群】。 ( 群完全免费,不广告不卖课!)




发表评论 取消回复