
服务器处理网站的问题
网络问题
robots.txt 指令阻止 Googlebot 访问页面

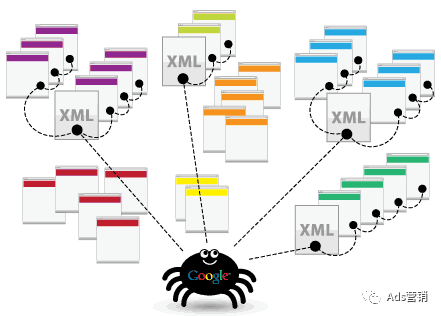
在索引过程中,Google 会确定一个页面是互联网上另一个页面的副本还是规范页面。规范是确定页面可能显示在搜索结果中。为了选择规范,谷歌首先将在互联网上找到的具有相似内容的页面进行聚类,然后选择最能代表该组的页面。该组中的其他页面是可以在不同搜索环境中提供替代版本。
Google 还会收集有关规范页面及其内容的信号,依据信号在搜索结果中提供该页面。信号包括页面的语言、内容所在的国家/地区、页面的可用性等。
收集到的有关规范页面及其集群的信息可能存储在 Google 索引中(这是一个托管在数千台计算机上的大型数据库)。并非 Google 处理的每个页面都会被编入索引。
索引还取决于页面的内容及其元数据。一些常见的索引问题可能包括:
页面内容质量低
机器人元指令不允许索引
网站的设计可能会使索引变得困难
当用户输入查询时,谷歌机器会在索引中搜索匹配页面,并返回谷歌认为质量最高且与用户最相关的结果。相关性由数百个因素决定,其中可能包括用户的位置、语言和设备(桌面或电话)等信息。例如,搜索“自行车维修店”会向巴黎用户显示与向香港用户显示不同的结果。
Search Console 可能会告诉您某个页面已编入索引,但您在搜索结果中看不到它。这可能是因为:
页面内容的内容与用户无关
内容质量低
机器人元指令阻止服务
文章为作者独立观点,不代表DLZ123立场。如有侵权,请联系我们。( 版权为作者所有,如需转载,请联系作者 )

网站运营至今,离不开小伙伴们的支持。 为了给小伙伴们提供一个互相交流的平台和资源的对接,特地开通了独立站交流群。
群里有不少运营大神,不时会分享一些运营技巧,更有一些资源收藏爱好者不时分享一些优质的学习资料。
现在可以扫码进群,备注【加群】。 ( 群完全免费,不广告不卖课!)






发表评论 取消回复