
1.了解 Google 如何分析网站
首先,可在移动设备友好测试(Mobile-Friendly Test)中测试网站,了解 Google 如何分析网站。Google 并不总能看到我们在浏览器中看到的网站所有内容。以下示例中,Google 不知道此页面上有图片,因为该页面使用了 Google 不支持的 JavaScript 功能。
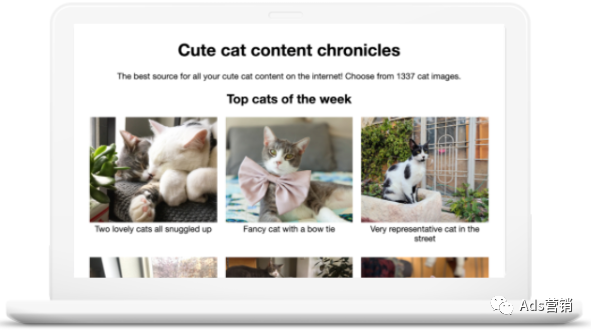
用户在浏览器中看到的网站内容

谷歌搜索抓取到的网站内容
2.检查网站链接
Googlebot 通过跟踪链接、站点地图和重定向在网址间导航。Googlebot 会将每个网址都作为在网站上看到的第一个也是唯一一个网址来处理。为了确保 Googlebot 能够找网站上的所有网址,请执行以下操作:
使用包含有效网址的 <a href>。
构建并提交站点地图,协助 Googlebot 更智能地抓取网站。
对于只有 1 个 HTML 网页的 JavaScript 应用,确保每个屏幕或每项具体内容都有一个网址。
3.检查如何使用 JavaScript
虽然 Google 确实运行 JavaScript,但在设计页面和应用程序需要考虑一些差异和限制,以适应爬虫访问和呈现内容的方式。
要详细了解 Google 在抓取、呈现和编制索引时如何处理 JavaScript,请观看以YouTube视频:https://youtu.be/Mqi9aLZElgc。
4.当内容发生更改后及时告知 Google
为确保 Google 快速找到新页面或更新后页面:
提交站点地图。
要求 Google 重新抓取您的网址。
在适用时使用索引 API。
如果仍然无法将页面编入索引,检查服务器日志是否有错误。
5.不要忘记页面上的文字
Googlebot 只能找到以文字形式显示的内容。
确保视觉内容附加文字形式的说明。例如,在商品类别网页中,每张图片都应附有一些文字说明。
确保每个网页都有描述性标题和元描述。独特的标题和元描述有助于 Google 显示网页与用户的相关程度,从而提升搜索流量。
使用语义 HTML。尽可能不要使用插件,而是尽可能为内容使用语义 HTML 标记。
6.将内容的其他版本告知 Google
Google 无法自动知晓网站或内容有多个版本。例如,网站的移动版本、桌面版本或多国语言版本。要确保 Google 向用户提供正确的版本:
整合重复网址。
将网站的本地化版本告知 Google。
使 AMP 网页可被轻松发现
7.控制 Google 抓取到的内容
有几种方法可以阻止 Googlebot:
若要禁止 Google 查找网页,请仅允许已登录的用户访问内容。
若要禁止 Googlebot 抓取网页,请创建robots.txt。
-
若要禁止 Google 将网页编入索引,但仍允许抓取,请添加 noindex 标记。
如果内容未显示在 Google 搜索中,而希望它显示:
使用 URL 检查工具检查 Googlebot 是否可以访问该页面。
测试robots.txt 文件,看看是否无意中阻止了 Googlebot 抓取网站。
检查 HTML 中元标记中的 noindex 规则。
8.为网站启用富媒体搜索结果
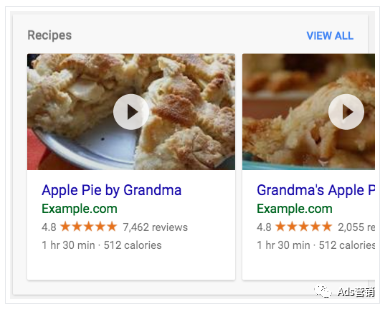
富媒体搜索结果可包含样式、图片或其他互动功能,帮助网站在搜索结果中脱颖而出。可以在网页上添加结构化数据,提供与网页含义有关的明确线索,从而帮助 Google 更好地了解网页并在 Google 搜索中显示富媒体搜索结果。
站长具体指南
避免使用以下技术:
意图利用自动生成的内容操纵搜索排名
参与链接方案
制作原创内容很少或没有原创内容的网页
伪装真实内容
欺骗性重定向
隐藏文字或链接
门页
抄袭内容
参与不能有效增值的联属计划
加载带有无关关键字的网页
制作会实施恶意行为(如钓鱼式攻击,或安装病毒、特洛伊木马或其他有害软件)的网页
滥用结构化数据标记
向 Google 发送自动查询
遵守最佳做法:
监控网站是否出现黑客攻击活动,并尽快移除被黑的内容
防止网站上出现用户生成的垃圾内容并及时予以移除
如果您的网站违反以上一条或多条指南,则 Google 可能会对该网站执行手动操作。解决这些问题后,您便可提交网站以供重新审核。
文章为作者独立观点,不代表DLZ123立场。如有侵权,请联系我们。( 版权为作者所有,如需转载,请联系作者 )

网站运营至今,离不开小伙伴们的支持。 为了给小伙伴们提供一个互相交流的平台和资源的对接,特地开通了独立站交流群。
群里有不少运营大神,不时会分享一些运营技巧,更有一些资源收藏爱好者不时分享一些优质的学习资料。
现在可以扫码进群,备注【加群】。 ( 群完全免费,不广告不卖课!)





发表评论 取消回复