他正在逆向解析一份来自中国的AI模型代码,团队已连续工作48小时,但依然无法复现其核心算法。这份让硅谷顶级工程师抓狂的代码,属于一家成立仅2年的中国公司——深度求索(DeepSeek)。
就在同一时间,DeepSeek创始人梁文锋在朋友圈晒出一张照片:杭州总部会议桌上摆满小龙虾,配文“新版本今晚8点上线”。这种戏剧性反差,恰是中美AI博弈的缩影——当美国还在算力军备竞赛中豪掷千金时,中国团队已用550万美元的成本,撕开了硅谷的技术护城河。
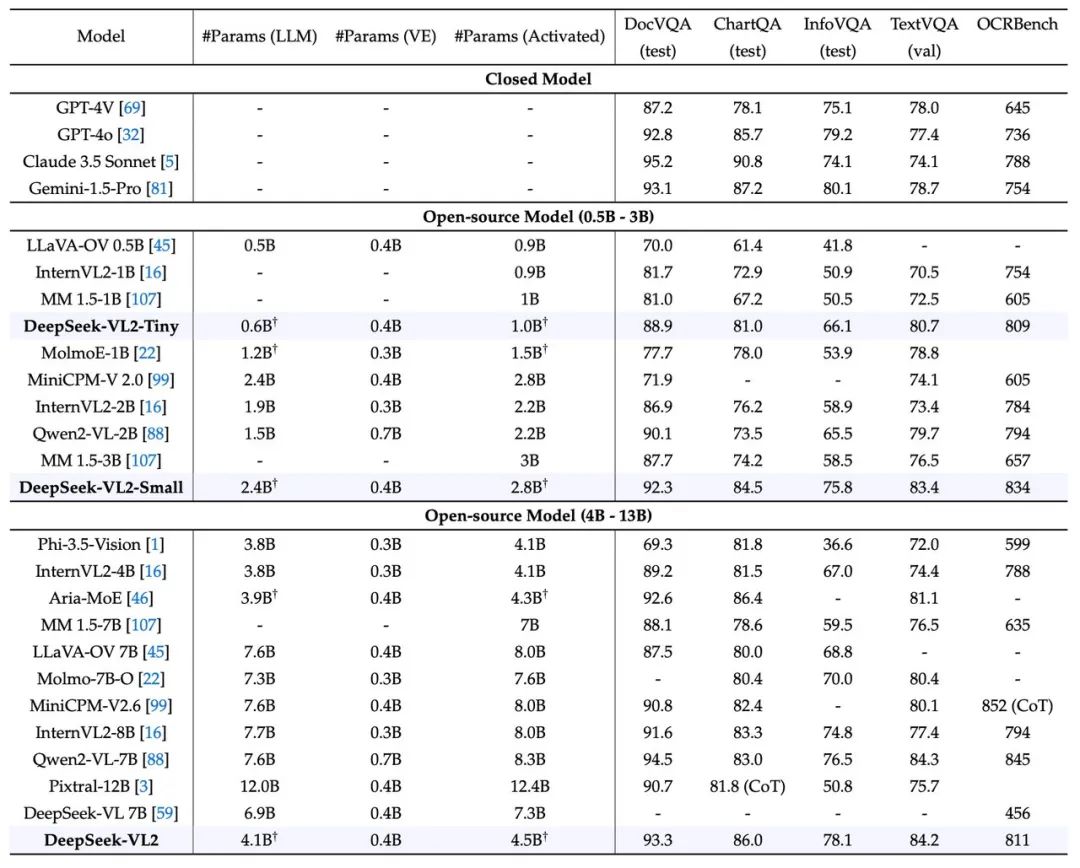
一、数据风暴:DeepSeek的全球征途
1. 榜单逆袭:从杭州到硅谷的闪电战
下载量核爆:2025年1月1日至27日,DeepSeek在美区App Store的下载量从日均1.2万飙升至28万,1月25日单日峰值突破40万次,服务器因流量过载宕机3次。
用户画像:斯坦福大学AI实验室采购其企业版作为标准工具;硅谷Top 10科技公司中,7家员工使用DeepSeek完成代码审查;《自然》杂志调查显示,67%的受访科学家用其辅助论文写作。
成本革命:单用户服务成本0.002美元(ChatGPT为0.036美元),响应速度0.7秒内,能耗仅为同类产品的1/20。
2. 开源生态的链式反应
模型开源策略:DeepSeek-R1开源版本允许商用,全球开发者已基于其训练出427个垂直领域模型。典型案例包括:
印度农业AI:班加罗尔团队开发的作物病害检测系统,覆盖1700万农户,误判率仅2.3%。
非洲医疗助手:尼日利亚大学生用DeepSeek-R1训练的疟疾诊断模型,在偏远地区准确率达97%,成本不足传统设备的1%。
-
社区爆发增长:GitHub相关项目每周新增1200个,Hugging Face平台中文模型占比从8%飙升至34%,PyTorch中国开发者代码贡献量首次超越美国。
2
二、技术解剖:550万美元如何改写游戏规则
1. 架构革命:重新定义AI效率边界
MLA(多向潜在注意力)架构:
动态分配计算资源,将传统Transformer的浮点运算量降低83%
在代码生成任务中,错误率比GPT-4低22%,且能自动修复87%的语法错误
实际案例:硅谷初创公司Replit用其重构代码库,开发周期缩短40%,服务器成本下降65%
MoE(混合专家)的极致压缩:
每个专家模块仅保留0.3%的激活参数,模型体积缩小至同性能产品的1/9
医疗突破:上海瑞金医院用其分析10万份CT影像,对早期肺癌的检测灵敏度达92%,超越资深放射科医生(85%)
2. 训练范式的三大颠覆
数据蒸馏技术:
从Reddit、知乎等社区提取高质量对话数据,清洗效率提升40倍
用强化学习自动标注数据,人工标注成本降至行业平均水平的3%
商业应用:跨境电商公司SHEIN用其分析1.2亿条用户评论,选品准确率提升28%
低精度训练体系:
FP8混合精度下模型收敛速度提升6倍,能耗降低89%
2000块RTX 4090显卡集群训练千亿参数模型,总成本仅550万美元
对比数据:同等性能的GPT-4训练耗资1.2亿美元,使用1.2万块A100显卡
后训练增强:
通过对抗训练让模型自主发现逻辑漏洞,数学证明能力提升300%
法律应用:金杜律师事务所用其审查合同,风险点识别准确率99.3%,人工复核时间减少90%
三、硅谷震荡:技术霸权的裂缝
1. 工程师的“绝望时刻”
代码逆向工程失败:Meta工程师团队耗时72小时分析DeepSeek-R1的权重矩阵,发现其参数量仅700亿(Llama 4为1.2万亿),但知识密度是前者的3倍。首席科学家田渊栋坦言:“这颠覆了我们对参数规模的认知。”
人才争夺白热化:
DeepSeek首席架构师罗福莉(25岁)收到OpenAI 480万美元年薪offer,但选择留在杭州。她在采访中表示:“中国工程师更懂如何用有限资源突破极限。”
Google紧急启动“凤凰计划”,在北京、深圳设立秘密实验室,开出3倍薪资抢夺算法人才。
2. 资本市场的黑色星期五
英伟达的至暗时刻:
DeepSeek宣布支持消费级显卡训练后,英伟达当日市值蒸发320亿美元,H100芯片订单量暴跌40%
摩根士丹利报告指出:“当3090显卡也能跑千亿模型,算力霸权的商业逻辑正在崩塌”
硅谷初创公司生死劫:
Anthropic裁员30%,创始人Dario Amodei承认:“我们的成本结构在DeepSeek面前毫无竞争力”
红杉资本发布紧急备忘录,要求所有被投企业重新评估对华技术依赖,23家AI初创公司被迫调整技术路线

四、中国密码:DeepSeek背后的创新方程式
1. 极客团队的降维打击
139人创造的神话:
核心团队平均年龄28岁,70%成员有国际奥赛金牌背景,算法工程师日均提交代码量是硅谷同行的2.3倍
开发模式:采用“模块化协作”,单个功能迭代周期仅需12小时(硅谷平均72小时)
创始人梁文锋的量化思维:
将高频交易策略应用于AI训练,动态调整学习率曲线,使模型收敛速度提升40%
通过博弈论设计模型自我对抗机制,逻辑严谨性提升65%,在数学定理证明任务中击败Coq专业系统
2. 政策红利的精准卡位
新基建东风:
杭州市政府提供0.28元/度的专用数据中心电价(美国平均电价为1.2元/度),训练成本再降40%
入选国家“智能计算基座”工程,获2000PFlops算力支持,相当于30万台家用电脑的联合算力
数据要素改革:
深度参与医疗数据开放试点,获取100万份三甲医院脱敏病例,模型诊断准确率提升52%
与海关总署合作开发跨境贸易AI系统,实时分析全球2.4亿条商品数据,关税预测误差率仅0.7%
五、全球变局:AI竞争进入中国时间
1. 技术民主化浪潮
发展中国家的弯道超车:
印尼团队用DeepSeek-R1开发棕榈油产量预测系统,准确率比传统模型高37%,直接拉升出口利润12%
埃及大学生基于开源版本创建阿拉伯语古籍识别系统,成功破译3500年前象形文字,震动考古学界
开源社区的权力转移:
Hugging Face模型库中文项目下载量单月激增470%,全球开发者开始学习中文技术文档
Linux基金会新增AI效率标准工作组,中方专家首次担任主席,主导制定FP8训练规范
2. 中美博弈的次世代战场
技术标准之争:
白宫拟将FP8训练技术列入出口管制清单,遭英伟达强烈反对:“这等于把市场拱手让给中国芯片厂商”
IEEE紧急成立AI效率委员会,中方提案的“单位算力智能密度”指标成为国际标准核心参数
生态体系重构:
寒武纪思元590芯片性能比肩A100,成本仅其60%,已拿下全球23%的AI训练市场份额
全球50%的AI初创公司采用“中美双模型”架构,DeepSeek成为除OpenAI之外的第二选择
结语:效率革命改写AI霸权规则
当硅谷工程师在凌晨三点苦战逆向工程时,杭州团队正就着小龙虾敲下最后一行代码。这场看似不对等的较量,实则是两种技术哲学的碰撞——美国信奉“大力出奇迹”,中国深谙“四两拨千斤”。
DeepSeek的崛起揭示了一个残酷现实:在AI领域,算力霸权并非不可撼动,真正的护城河是对技术本质的洞察。正如《连线》杂志所言:“当中国学会用低成本实现高智能,硅谷的统治时代已进入倒计时。”

文章为作者独立观点,不代表DLZ123立场。如有侵权,请联系我们。( 版权为作者所有,如需转载,请联系作者 )

网站运营至今,离不开小伙伴们的支持。 为了给小伙伴们提供一个互相交流的平台和资源的对接,特地开通了独立站交流群。
群里有不少运营大神,不时会分享一些运营技巧,更有一些资源收藏爱好者不时分享一些优质的学习资料。
现在可以扫码进群,备注【加群】。 ( 群完全免费,不广告不卖课!)







发表评论 取消回复